在訓練過程中沒有所謂的標準答案,故機器會自己從資料群中找出一套分群的法則。非監督式學習的優點是不需要事先以人力標籤,只給定特徵讓機器想辦法會從中找出規律。常見的非監督式的分群演算法有 K-means,它根據物以類聚的原理目標是根據特徵把資料樣本分為 K 群。其中在訓練模型時僅須對機器提供輸入的特徵,並利用分群演算法自動從這些特徵中找出鄰近的集群中心作為該類別。
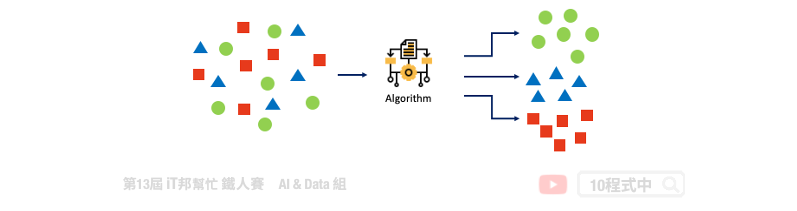
透過分群分類演算法我們能夠將多種維度的資料進行分類。K-means 演算法的概念很簡單也非常容易實作,僅一般加減乘除就好不需複雜的計算公式。
重複步驟2、3,直到資料點不再變換群組為止

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris
我們今天要實作分群分類的問題,因此鳶尾花朵資料集非常適合當作範例。其資料集載入方式在第四天有提過,是一樣的內容!
iris = load_iris()
df_data = pd.DataFrame(data= np.c_[iris['data'], iris['target']],
columns= ['SepalLengthCm','SepalWidthCm','PetalLengthCm','PetalWidthCm','Species'])
df_data
K-means 演算法在 Sklearn 套件中已經幫我們封裝好了,使用者只要呼叫 API 即可將分群分類演算法快速實作。
Parameters:
Attributes:
[n_clusters, n_features]。Methods:
from sklearn.cluster import KMeans
kmeansModel = KMeans(n_clusters=3, random_state=46)
clusters_pred = kmeansModel.fit_predict(X)
使用者設定 K 個分群後,該演算法快速的找到 K 個中心點並完成分群分類。擬合好模型後我們可以計算各個樣本到該群的中心點的距離之平方和,用來評估集群的成效,其 inertia 越大代表越差。
kmeansModel.inertia_
輸出結果:
78.94084142614602
若要查看各群集的中心點,可以參考以下程式碼。
kmeansModel.cluster_centers_
輸出結果:
array([[5.9016129 , 2.7483871 , 4.39354839, 1.43387097],
[5.006 , 3.428 , 1.462 , 0.246 ],
[6.85 , 3.07368421, 5.74210526, 2.07105263]])
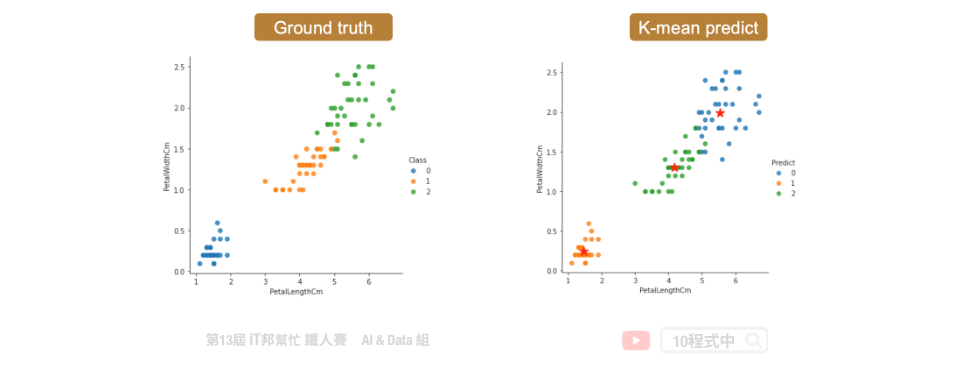
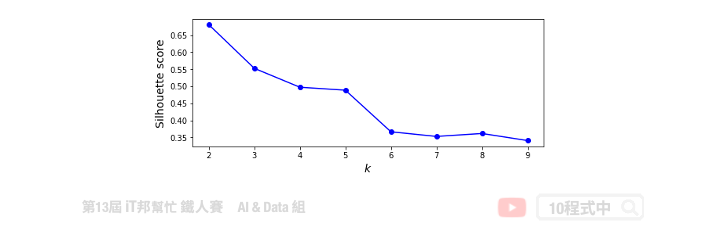
當你手邊有一群資料,且無法一眼看出有多少個中心的狀況。可用使用下面兩種方法做 k-means 模型評估。
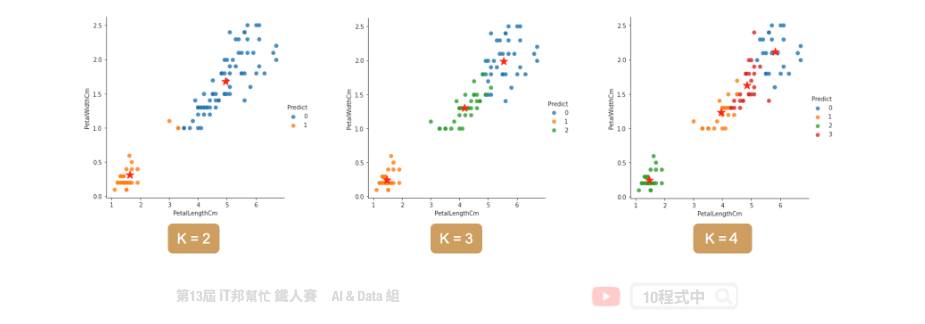
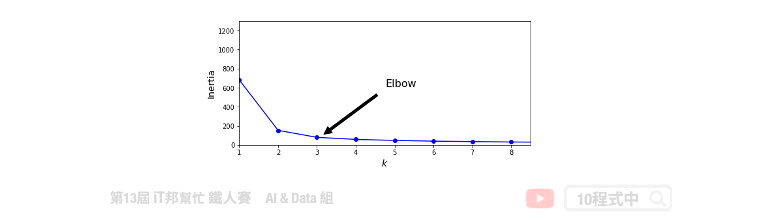
當K值越來越大,inertia 會隨之越來越小。正常情況下不會取K最大的,一般是取 elbow point 附近作為 K,即 inertia 迅速下降轉為平緩的那個點。
# k = 1~9 做9次kmeans, 並將每次結果的inertia收集在一個list裡
kmeans_list = [KMeans(n_clusters=k, random_state=46).fit(X)
for k in range(1, 10)]
inertias = [model.inertia_ for model in kmeans_list]
另外一個方法是用 silhouette scores 去評估,其分數越大代表分群效果越好。
from sklearn.metrics import silhouette_score
silhouette_scores = [silhouette_score(X, model.labels_)
for model in kmeans_list[1:]]
文章同時發表於: https://andy6804tw.github.io/crazyai-ml/6.非監督式學習k-means分群
如果你對機器學習和人工智慧(AI)技術感興趣,歡迎參考我的線上免費電子書《經典機器學習》。這本書涵蓋了許多實用的機器學習方法和技術,適合任何對這個領域有興趣的讀者。點擊下方連結即可獲取最新內容,讓我們一起深入了解AI的世界!
👉 全民瘋AI系列 [經典機器學習] 線上免費電子書
👉 其它全民瘋AI系列 這是一個入口,匯集了許多不同主題的AI免費電子書


 iThome鐵人賽
iThome鐵人賽